
Document processing is a common LLM use case, but most implementations rely on disconnected components: an OCR engine extracts text, a separate model tries to make sense of it, and layout information that would help resolve ambiguities gets lost in between.
This case study presents an architecture that addresses this fragmentation using the Qwen3 model family. The choice is pragmatic—its consistent tokenization allows clean handoffs between specialized models in the same pipeline, so visual understanding, linguistic reasoning, and verification can operate in concert.
The design employs Qwen3-VL as a perception layer for layout-aware OCR, a Qwen3 text model as a cognition layer for efficient processing, and Qwen3-Omni as an arbitration layer invoked only when earlier stages flag ambiguities. This selective approach controls inference costs while maintaining integration between visual and textual context.
The following sections detail component specifications, data flows, storage strategies, and operational patterns.
Context and Objective
This case study presents a hybrid, orchestrated architecture that leverages the unified Qwen3 model family to apply specialized processing where it is most effective: multimodal analysis for visual understanding and efficient text-only processing for linguistic reasoning. The objective is to build a web-based system that ingests scanned documents (PDFs and images), extracts text and structure with high accuracy, derives intelligent summaries and metadata, and stores everything in a searchable, versioned database.
Core Requirements
- Accurate OCR with Layout Understanding: Handling multi-page documents, tables, and complex layouts while preserving structural relationships.
- Intelligent, Grounded Processing: Generating high-quality summaries and structured metadata that are traceable to source content.
- Production Robustness: Supporting reprocessing, versioning, monitoring, and cost-effective operation.
- Unified Search: Enabling efficient semantic and keyword search across raw, extracted, and processed data.
Model Selection Logic: The Unified Qwen3 Family
The Qwen3 family provides a consistent suite of models with unified tokenization and training methodologies. This allows for clean handoffs and shared representations between specialized variants within the same pipeline, compared to assembling disparate models from different ecosystems. The architecture is orchestrated—each model is selected for a specific processing mode.
Vision + OCR and Layout: Qwen3-VL
Serves as the primary Perception Layer. It establishes the ground truth of document content and structure through multimodal analysis, outperforming traditional OCR engines on complex layouts by jointly understanding text and visual arrangement.
Text-Only LLM: Qwen3 Core
Serves as the efficient Cognition Layer. After Qwen3-VL provides text and layout, this dedicated text model performs cleanup, summarization, and structured extraction, offering a cost-effective approach for purely linguistic tasks without image-processing overhead.
Multimodal Verification: Qwen3-Omni
Serves as a targeted fallback when text and visual context are inseparable—invoked selectively as an Arbitration Layer to resolve ambiguities flagged by earlier stages, ensuring final output reliability without universal multimodal costs.
Embedding Model: Qwen3 Text Embeddings
Generates vector representations for semantic search. Using a model from the same family ensures consistent tokenization and optimal performance for the multilingual text processed by the pipeline.
Production Architecture
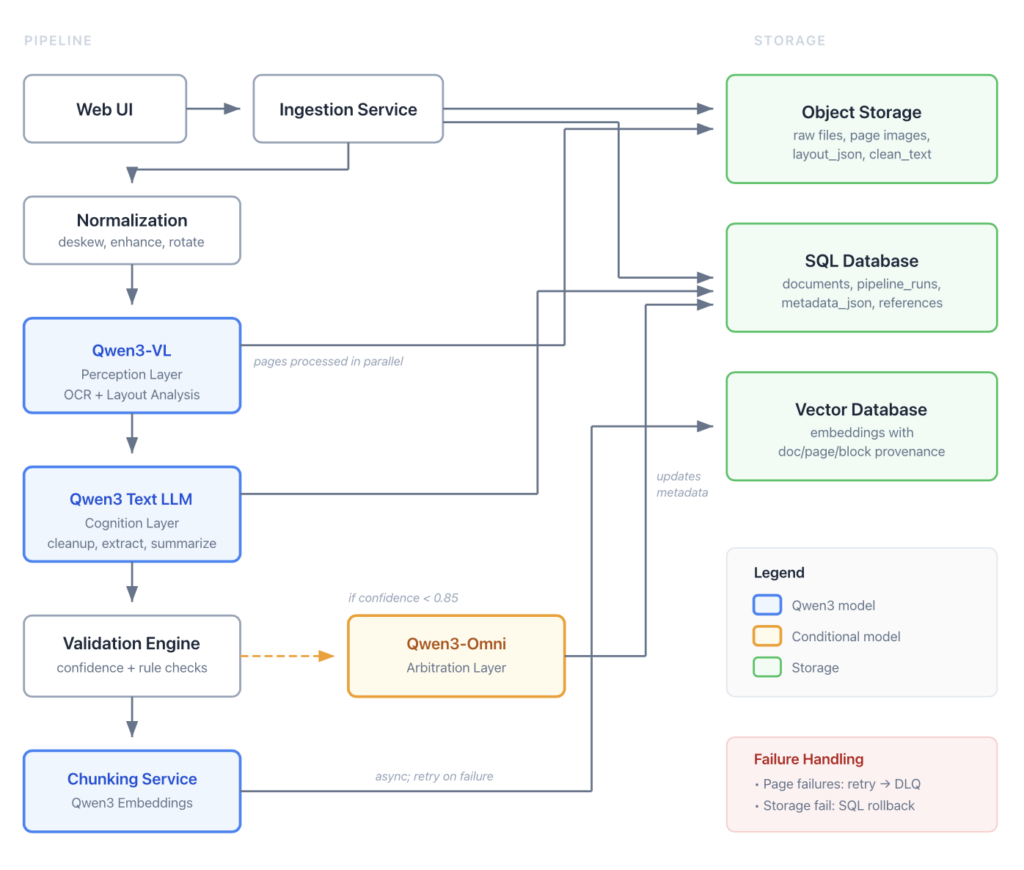
This pipeline emphasizes modularity, traceability, and robust error handling. The flow is designed to be idempotent and version-aware.
1. User Upload and Tracking
A Web UI accepts PDF and image uploads. The Ingestion Service immediately inserts a record in the documents SQL table with status=RECEIVED, source_uri (path in object storage), source_sha256, and timestamps. The raw file is stored in Object Storage, providing scalable storage and decoupling the database from large binaries.
2. Normalization and Preprocessing
For PDFs, a Normalization Service renders each page to a standardized image format. It applies configurable image preprocessing: deskew, contrast enhancement, rotation correction. Output: A consistent set of image files per document, ready for vision model ingestion.
3. OCR and Layout Analysis (Qwen3-VL – Perception)
Model: The Qwen3-VL service processes each page image in multimodal mode. Pages can be processed in parallel for throughput.
Output: A structured JSON representation of the document layout, including pages[] containing blocks[] with bounding boxes, type (paragraph, heading, table), text, confidence scores, and inferred reading order.
Storage Strategy: The detailed layout_json is stored in object storage, with its URI and metadata in SQL. The raw concatenated ocr_text reference is stored in SQL. This is the canonical source of extraction.
Failure Handling: Failed page processing is retried (max 3 attempts). Documents with persistent failures are moved to a dead-letter queue for manual inspection, allowing partial success for multi-page documents.
4. Text Cleanup, Summarization, and Extraction (Qwen3 Text LLM – Cognition)
Model: A Qwen3 text LLM processes the ocr_text in text-only mode.
Tasks:
- Cleanup: Fixes hyphenation, line breaks, and common OCR artifacts.
- Structured Extraction: Extracts key entities into a validated
metadata_jsonschema. - Summarization: Generates a concise, structured summary.
- Flagging: Tags low-confidence extractions or inconsistencies for potential verification.
Confidence Scoring: A composite heuristic score is calculated per extracted field, combining the Qwen3-VL block confidence, the text LLM’s self-assessment (elicited via prompts that ask the model to rate extraction certainty), and rule-based validations (e.g., date format checks).
Storage: clean_text is stored in object storage. metadata_json and summary_text are stored in SQL. All are linked by a pipeline_execution_id.
5. Selective Multimodal Verification (Qwen3-Omni – Arbitration)
Trigger: A Validation Engine invokes this targeted step based on explicit policies:
- Confidence Threshold: Any critical field with a composite confidence score < 0.85 (a configurable parameter).
- Logical Inconsistency: A rule engine detects anomalies (e.g., a date in the future).
- Explicit Flag: The
layout_jsoncontains a block of typehandwritingorstamp.
Process: The service retrieves the original image region (using bbox from layout_json) and the disputed text/field.
Model: Qwen3-Omni performs focused re-analysis in multimodal mode, and its output updates the metadata_json.
6. Storage, Search, and Data Consistency
The system employs a multi-store strategy with clear consistency guarantees.
SQL Database (Authoritative Record)
Stores: Structured metadata, relational data, status flags, timestamps, and references.
Key Tables: documents, pipeline_runs, artifacts, metadata_entities.
Consistency: All database writes for a single document occur within a transaction boundary. If writing to object storage fails, the SQL transaction rolls back to prevent orphaned references.
Object Storage (Heavy Payloads)
Stores: Original files, page images, large JSON blobs (layout_json), and full text blobs (clean_text).
Heuristic: Data > 10KB (a threshold balancing database row efficiency against object storage latency) that isn’t frequently joined in relational queries resides here. SQL maintains reference pointers.
Vector Database (Semantic Search)
Content: The Chunking Service generates embeddings from semantically chunked clean_text.
Chunking Strategy: A deterministic hybrid approach: primary breaks at layout-defined heading blocks, secondary breaks using semantic boundary detection (e.g., using sentence similarity), with fixed-size sliding windows as a fallback.
Metadata: Each vector includes document_id, page_number, and block_id for precise provenance.
Consistency: Updates are asynchronous. A failed vector insert does not roll back the main transaction but triggers a compensating action to retry or flag the inconsistency.
7. Operational Considerations
Versioning and Reprocessing
Every artifact records model_name, model_version, and prompt_hash. Prompts are versioned in a git repository and validated before deployment. Reprocessing creates a new pipeline_run, enabling A/B testing of model versions.
Security and Compliance
- PII Handling: A post-processing scan identifies and can redact sensitive fields.
- Encryption: All data is encrypted at rest and in transit.
- Access Control: Role-based access control (RBAC) is enforced at the document and artifact level.
- Audit Logging: All system actions, including document access and model invocations, are logged to an immutable store.
Monitoring and Cost Control
- Key Metrics: Qwen3-VL confidence distribution, LLM token usage, Qwen3-Omni trigger rate, end-to-end latency (batch: < 5 min, real-time: < 30s).
- Circuit Breakers: The Qwen3-Omni service has usage-based circuit breakers to prevent cost overruns.
- Concurrency: The pipeline supports configurable parallel processing at both the document and page level to optimize throughput for batch operations.
Summary
This architecture implements a clear separation of concerns using the specialized Qwen3 model family in an orchestrated pipeline:
- Qwen3-VL as the Perception Layer establishes the authoritative document representation through multimodal analysis.
- Qwen3 Text LLM as the Cognition Layer efficiently performs linguistic reasoning in text-only mode.
- Qwen3-Omni as the Arbitration Layer provides targeted multimodal verification for edge cases.
- Qwen3 Embeddings enable semantic search within the same model family ecosystem.
By linking all data through a versioned relational model, implementing robust failure handling, and maintaining clear storage heuristics, the system achieves production-ready robustness while preserving full traceability from outputs back to source document regions.