
Quantization is a common step in local LLM deployment, but most approaches treat it as compression: reduce precision, verify the model loads, move on. This misses how transformers behave under reduced precision—errors compound across layers and context length in ways that basic testing doesn’t reveal.
This case study presents a methodology for reliable local deployment developed through quantization work across multiple model families. The focus is systematic: matching infrastructure constraints to quantization choices, calibrating against representative workloads at target context lengths, and validating against task-specific criteria rather than aggregate metrics alone.
The following sections detail infrastructure requirements, capacity planning, quantization strategy, and operational patterns.
Context and Objective
The approach treats quantization as a system design decision with behavioral consequences. Precision interacts with model size, context length, and task characteristics to determine whether a configuration will hold up in production—particularly for long-context workloads where precision effects accumulate.
The objective is to bridge the gap between infrastructure constraints and model requirements while maintaining predictable behavior under production conditions.
Core Requirements
- Infrastructure sized for memory bandwidth, not just capacity
- Capacity planning that accounts for KV cache growth under production context lengths and concurrency
- Quantization selection based on task sensitivity and target context lengths
- Calibration against representative data at deployment context lengths
- Validation that catches task-specific failures, not just perplexity regression
- Serving configuration matched to quantization and memory constraints
Infrastructure Architecture
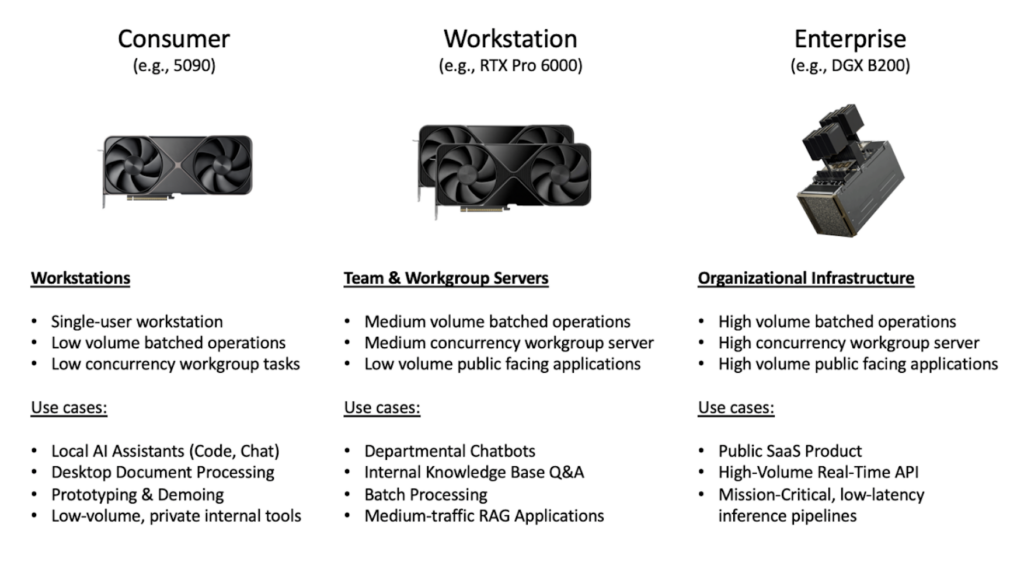
Infrastructure constraints frame every subsequent decision about model selection and quantization. The gap between a target model’s requirements and available infrastructure capabilities dictates the quantization strategy.
Memory Systems
Memory capacity determines which models can load. Memory bandwidth determines how fast they generate.
Autoregressive generation reads model weights from memory for each token produced. This creates a hard ceiling on generation throughput: memory bandwidth divided by model size. The relationship holds regardless of available compute capacity. Overinvestment in compute while bandwidth remains the binding constraint is a common planning error.
Bus width and interface generation determine available bandwidth. When evaluating hardware for inference workloads, bandwidth specifications matter as much as capacity specifications. A system with ample capacity but constrained bandwidth will load large models successfully but generate slowly.
Multi-Device Configurations
Multiple devices can be aggregated through tensor parallelism or pipeline parallelism when single-device memory is insufficient. This introduces coordination overhead as devices must synchronize during inference. Whether aggregation improves overall capability depends on the relationship between this overhead and the gains from running a larger model.
Interconnect topology affects multi-device performance. Bandwidth is frequently shared between physical slots on the same bus. Effective lane counts may be lower than physical slot sizes indicate, and populating multiple slots may reduce per-slot bandwidth. Routing through chipset controllers rather than direct CPU attachment introduces additional latency. These factors matter less for inference than training because models load once into device-local memory and execute there. Training workloads require continuous high-bandwidth inter-device communication for gradient synchronization.
Platform selection involves a counterintuitive tradeoff. Newer platforms with faster interconnects sometimes provide fewer usable expansion slots due to signal integrity requirements and physical layout constraints. Deployments requiring multiple accelerators may find that older platform generations offer superior device density even at lower per-slot bandwidth.
Power and Thermal
Power delivery constrains feasible configurations at every scale. The complete chain matters: facility supply, distribution infrastructure, and power conversion equipment. Undersizing any link produces intermittent failures that manifest only under peak load or transient conditions.
Power conversion equipment should be sized with headroom above maximum expected draw. Accelerators frequently exceed their rated TDP during load transitions. Equipment sized close to average load may shut down during these transients. Operating power conversion at 50-70% of rated capacity provides necessary headroom while maintaining efficiency.
Multi-PSU configurations require consistent grounding between power sources; differences in ground potential can damage components connected to both. Power-up timing between sources must be synchronized to prevent unstable states during initialization. Sync cables or relay triggers provide the necessary coordination.
Thermal management becomes critical in dense configurations. Multiple accelerators in close proximity generate substantial heat, and inadequate cooling causes thermal throttling that reduces throughput unpredictably. Physical spacing between devices reduces thermal interaction when slot density permits.
Power limiting provides useful flexibility. Many accelerators support operating below their default power envelope with corresponding reductions in throughput. The relationship is often favorable, with throughput reduction smaller than power reduction. This allows fitting additional devices within a fixed power budget or maintaining acceptable temperatures in cooling-constrained environments.
Inference workloads place minimal demand on host CPU and system memory once models load into accelerator memory. For dedicated inference systems, this frees budget for additional accelerator capacity or faster memory interfaces.
Capacity Planning
Memory requirements for inference derive from two sources: model weights and key-value cache.
Weight memory footprint is deterministic: parameter count multiplied by bytes per parameter at the target precision. A model’s parameter count is fixed; precision is the variable under operator control.
KV cache memory footprint scales with model architecture, precision, context length, and concurrent batch size. The scaling relationships are architecture-specific but documented and predictable.
In production configurations, KV cache frequently dominates total memory consumption. A model that fits comfortably at short context lengths may exhaust available memory when serving longer contexts or handling multiple concurrent requests. Capacity planning must account for worst-case operational parameters rather than weight footprint alone.
Queue theory applies to inference serving. Sizing capacity to average load produces latency degradation during demand peaks. Required headroom depends on acceptable latency variance and peak-to-average load ratios.
Quantization Strategy
When capacity requirements exceed infrastructure constraints, quantization bridges the gap by trading precision for memory reduction. Several quantization approaches exist, each with different cost and accuracy profiles: post-training quantization (PTQ) applies after training completes, quantization-aware training (QAT) incorporates precision constraints during training, and weight-only quantization differs from weight-activation quantization in what gets reduced. The choice affects both the quantization process and the resulting model behavior.
Precision and Model Behavior
Quantization is sometimes explained through analogy to image compression. The comparison is misleading.
Consider a simple pixel-wise image compression that reduces each pixel’s color depth independently. Errors in one pixel do not affect neighboring pixels because each is processed in isolation.
Transformer models have fundamentally different structure. They operate in high-dimensional representational space where connections extend across the entire model. Weights are not isolated. During a forward pass, weights process every token in the sequence, and computations propagate through multiple layers with dynamic interactions. Reducing precision changes values that affect these interconnected computations throughout the model. The impact on behavior depends on complex interactions that cannot be predicted from examining individual weights. This is why quantization requires calibration rather than uniform precision reduction.
Model size affects sensitivity to quantization. Larger models tend to be more robust to precision reduction than smaller models, likely because they have greater representational capacity and parameter redundancy. The same quantization approach applied to models of different sizes produces different degrees of degradation. In some cases, a larger model at reduced precision outperforms a smaller model at full precision. In other cases, aggressive quantization renders smaller models unreliable. This is an observed tendency rather than an absolute rule.
Context length interacts with precision. Errors introduced by reduced precision accumulate over sequence length. Position encoding schemes such as RoPE apply rotary transformations to query and key vectors, encoding relative position into attention computations. Precision errors in these transformations affect attention patterns, and the effects compound as context grows. A quantization configuration that performs well for short-context tasks may produce noticeable degradation at longer contexts. Validation must cover the actual context lengths the deployment will serve.
Hardware support for precision formats affects both throughput and accuracy. Native hardware acceleration for a given precision format outperforms software emulation or fallback implementations on both dimensions. Some formats may use optimized lookup tables or specialized microcode rather than simple native operations, but the performance advantage remains. Current-generation architectures provide native support for precision formats that previous generations must approximate through different schemes. The same nominal bit width produces different results depending on hardware capabilities. The optimal quantization format depends on what the target hardware supports natively.
Some quantization schemes provide excellent throughput but introduce accuracy degradation that compounds over long contexts, making them unsuitable for extended reasoning tasks despite their performance advantages.
Calibration
Calibration evaluates how precision reduction affects model behavior across representative inputs. It is integral to producing quantized models with predictable behavior.
The process is computationally intensive because of the interdependent nature of transformer computations. Calibration cannot operate on individual weight values or isolated groups. It must evaluate how reduced precision impacts overall model behavior across the operational range.
Quantizing models requires sufficient combined host and device memory to load the full-precision model during the quantization process. Many modern quantization tools can run calibration directly on GPU or accelerator memory when available, which is faster than running on system RAM. The accelerator memory ceiling that motivates quantization does not apply during quantization itself.
Calibration data composition directly affects quantized model behavior. Generic calibration datasets produce results optimized for generic inputs. Domain-specific calibration data produces better-behaved quantized models for deployments serving that domain.
Calibration datasets require appropriate coverage of the model’s context length. Sequences should be tokenized using the model’s actual tokenizer and should fill the context window the deployment will use. Short calibration sequences do not adequately represent model behavior at long contexts.
A common methodology generates full-context-length token sequences for calibration—for example, around 100-200 rows at the model’s maximum supported context length, though the specific number varies by tool and model. Some methods require far fewer tokens. The key principle is coverage of the operational context window. The calibration process reads context length from the model’s configuration, applies the model’s tokenizer to source text, and produces properly formatted datasets.
Validation
Perplexity provides a useful baseline metric for quantization quality, capturing overall model degradation in a single number that enables comparison between precision configurations. Significant deviation from expected ranges for a given quantization approach indicates problems with calibration or quantization.
However, perplexity measures average-case language modeling quality, not task-specific performance. A model with acceptable perplexity may fail on tasks that matter to the deployment. Perplexity is necessary for sanity checking but not sufficient for validation.
Validation requires baseline comparison. The full-precision model should be evaluated against a representative task suite before quantization, with quantized variants compared against that baseline. Acceptable degradation thresholds depend on application and task characteristics.
Different task categories have different sensitivity. Classification, extraction, and structured output tasks frequently show minimal degradation even under aggressive quantization. Tasks requiring extended reasoning over long contexts are more sensitive, particularly to quantization schemes where accuracy degradation compounds over sequence length.
Edge case testing is necessary. Precision-sensitive operations may succeed on typical inputs while failing on specific patterns. Validation suites should include adversarial or boundary cases relevant to target workloads.
Performance measurements should accompany quality measurements. Quantization affects throughput, time-to-first-token, and maximum sustainable concurrency. The relationships vary with hardware configuration and native precision format support.
Concrete Example
A common pattern illustrates the tradeoffs: aggressive weight-only quantization may work well for classification and extraction tasks while degrading reasoning quality over long context windows. The same model might require more conservative quantization—or a different quantization scheme entirely—to maintain accuracy on multi-step reasoning at longer sequences. Short-context validation passes in both cases; the divergence only appears under production context lengths.
Deployment and Operations
Workload Matching
Constrained deployments handle focused tasks well: summarization, classification, translation, sentiment analysis, named entity recognition, and conversion of unstructured data to structured formats. These task categories tolerate aggressive quantization and operate effectively on smaller models. RAG architectures offset context and model size limitations.
Development, prototyping, and testing environments have different requirements than production. The objective is adequate capability for iteration rather than production throughput. Hardware configurations insufficient for production may work fine for development.
Complex reasoning, long-context processing, and high-concurrency production workloads require larger models, more conservative quantization, or scaled infrastructure. The sensitivity of long-context tasks to precision degradation makes quantization selection particularly important.
Serving Configuration
Inference server configuration interacts with quantization choices. Context length limits, concurrency settings, memory utilization targets, and batching behavior all affect what model configurations fit within available memory.
Context length configuration deserves particular attention. Longer context limits increase KV cache memory consumption. A model that fits at one context limit may exceed memory at a higher limit. The context length used for calibration should match the context length configured for serving.
Concurrency limits determine how many simultaneous requests the server will accept. Each concurrent request consumes KV cache memory. Memory must accommodate the model weights plus KV cache for the maximum number of concurrent requests at the maximum context length.
Continuous batching (also called iterative batching) is critical for throughput in production LLM serving. Unlike static batching, which waits for a batch to complete before accepting new requests, continuous batching allows new requests to enter processing as slots become available. This interacts directly with KV cache management: the server must track per-request cache state and manage memory dynamically as requests complete at different times. Memory planning must account for this dynamic allocation pattern.
Memory utilization settings control how aggressively the server uses available memory. Conservative settings leave headroom for allocation variability; aggressive settings maximize model size or concurrency at the cost of stability risk under peak load.
Validation should occur under realistic load conditions with production-representative serving configurations.
Operational Lifecycle
Quantized models are derived artifacts with dependencies on source models, calibration data, and quantization tooling. All three must be versioned and tracked. Changes to any upstream component may require regeneration and revalidation of downstream artifacts.
Source models receive updates from their publishers. Quantization tooling evolves. Calibration approaches improve. Each change potentially invalidates previous work. The operational framework must address reproducibility and verification over time.
A regression test suite for quantized model quality is necessary. Each quantized artifact should maintain traceability to its source model version, calibration dataset, tooling version, and validation results.
Monitoring should track latency percentiles, throughput, queue depth, and memory utilization. Capacity trend monitoring enables proactive scaling before demand exceeds capability.
Rollback capability is essential. When newly quantized models underperform predecessors in production, rapid reversion limits impact. This requires maintaining previous artifacts alongside their deployment configurations.
Summary
Quantization extends the capability of fixed hardware, but getting reliable results requires more than reducing precision and checking that models load. The interaction between precision, model size, context length, and task characteristics determines whether a quantized model will hold up in production.
Systematic attention to infrastructure constraints, calibration methodology, and task-specific validation produces deployments that work reliably. Skipping steps produces systems that pass basic testing but fail under production conditions, particularly for long-context workloads where precision effects compound.